
A huge amount happened in the Lean theorem prover community in 2023; this blog post looks back at some of these events, plus some of what we have to look forward to in 2024.
Modern mathematics
I personally am a member of the Lean community because of its phenomenal mathematics library mathlib, which was born around six and a half years ago and has now become a very fast-growing database of mathematics, containing many (but by no means all) of the definitions used by modern research mathematicians today. 2023 was the year where we really began to accrue evidence that formalisation of certain parts of serious modern mathematics is feasible in “real time”. Quanta’s video on 2023’s biggest breakthroughs in mathematics talks about several results; let’s take a look at their status when it comes to formalisation in Lean.
The first result in the Quanta video is the result by Campos–Griffiths–Morris–Sahasrabudhe giving an exponential improvement for upper bounds for Ramsey numbers. The previous post on this blog, by Bhavik Mehta, discusses his formalisation of the result; he formalised the 50+ page paper in five months (before the paper had even been refereed).
The second result in the video is the work by Smith, Myers, Kaplan and Goodman-Strauss on aperiodic monotiles. Myers has developed enough of the theory of planar geometry to formalise the solution to a 2019 IMO problem, and announced earlier this week his intention to formalise the result in Lean in 2024.
The third and final result mentioned in Quanta’s round-up was the Kelley–Maka result on bounds for how big a set of positive integers must be before it must contain a 3-term arithmetic progression. A formalisation of the result is being actively worked on by Yael Dillies; they have made substantial progress.
However, when it comes to formalising mathematics in real time, we now have an even more spectacular data point: Terry Tao led a team which formalised the main result in his breakthrough new paper with Gowers, Green and Manners proving Katalin Marton’s polynomial Freiman-Ruzsa conjecture. The 33 page paper was formalised in just three weeks (before the paper had even been submitted)! Tao used Patrick Massot’s Lean blueprint software to make this web page which contains a LaTeX/Lean hybrid document, containing an explanation of the proof which is comprehensible to both a human and a computer. He also made very effective use of the Lean Zulip, with summaries posted every few days of what was ready to be worked upon; ultimately 25 people contributed.
Based on these and other stories coming out of the mathlib community, one can come to the conclusion that there are parts of the modern theory of combinatorics (and in particular additive combinatorics) for which asking for a complete computer formalisation is not an unreasonable thing to do. Mehta and Bloom also formalised Bloom’s proof of the Erdos-Graham unit fractions conjecture, which for me is evidence that some parts of analytic number theory are also becoming amenable to this technique.
Fermat’s Last Theorem
However not all of modern mathematics is ready to be eaten by these systems. For example in September I was awarded a grant by the EPSRC (the UK mathematics funding body) to spend five years of my life formalising a proof of Fermat’s Last Theorem in Lean! Lean has the definitions of elliptic curves and modular forms required to start us off, but we are still working on other definitions, such as automorphic representations, finite flat group schemes and the like. I cannot yet link to a blueprint because the project does not officially start until October 2024 and right now I’m more worried about teaching my undergraduate Lean course, but I am part way through writing one and right now the graph looks like this:

People familiar with Tao’s blueprint graph will know that green means “done” and blue means “ready to be done”. The new orange colour means “a long way away”. Already we see the first major bifurcation: we need Mazur’s theorem on the torsion subgroups of elliptic curves over the rationals, a huge project, and completely independent of the 
The Focused Research Organisation
In July 2023 the Lean Focused Research Organisation (FRO) was launched. Focused Research Organisations are a new type of nonprofit for science, backed by Convergent Research. Lean’s FRO is funded by the Simons Foundation, Sloan, and Richard Merkin. This has enabled a team of people to work full-time on supporting the ever-growing Lean infrastructure and focus on many things (such as making the mathematics library compile faster, and adding infrastructure and tactics to enhance the user experience: I give some examples below). The FRO is hiring, by the way. One example of the ways that the FRO has made my own life easier: Scott Morrison has developed omega for Lean 4, a tactic for proving obvious-to-mathematicians lemmas about integers and naturals; these things will no longer slow down my undergraduate students.
In fact July 2023 was an amazing month for the community, because as well as the announcement of the FRO, it marked the end of the project to port all of Lean’s mathematics library from the now end-of-life Lean 3 to Lean 4.
Growing user base in computer science
But let’s get back to 2024. Sometimes it felt to me that Lean 3 was viewed as “a tool for mathematics”, with its mathematics library the flagship project. But both the FRO and other researchers in computer science are contributing code and tools to make Lean much more than this. Between 9th and 12th January 2024, the Lean Together 2024 conference showcased some of what was currently going on. As well as talks by mathematicians on growing the mathematics library, there were plenty of talks by computer scientists on tools or projects which they have been working on with Lean. For example, David Thraine Christianson from the FRO presented Verso, his domain-specific language for documentation. Static blog posts such as Tao’s Lean 4 proof tour can now be enhanced using this tool. Take a look at Joachim Breitner’s blog post about recursive definitions on the Lean-lang web page: this contains “live” code (hover over it!) and the entire post was generated from a Lean file; if the language updates and the code breaks then a warning will be generated. Perhaps in the future, infrastructure developed using Alex Best’s leaff tool (also presented at the conference) could even be used to suggest fixes.
Other non-mathematical highlights for me at the conference: Emina Torlak gave a presentation about how Amazon are using Lean in their Cedar project; Evgenia Karunus and Anton Kovsharov spoke about Paperproof, their visualisation tool for Lean proofs (which undergraduates seem to really like when I show it off in talks), and Kaiyu Yang spoke about LeanCopilot, an LLM tool trained on Lean’s mathematics library, whose main goal is to generate Lean proofs. I have always been skeptical of people who want to claim “Lean + AI = AGI”; in fact I’ve been maximally on the other side of the argument, with my opinion being that LLMs are right now of essentially no use to me as a working mathematician. But because I thought my undergraduates might like what I’d seen in the talk, I added LeanCopilot as a dependency for the repository I’m using in my undergraduate course, and it really can do a bunch of the problems (sometimes in totally different ways to my model solutions). I also tried it on a question someone asked on the Lean Zulip chat and it solved that too — and quickly. I think it will be interesting to see whether future versions of these tools will actually be of use to me in the Fermat project I mentioned above (which is funded until 2029; who knows what language models will be capable of then).
What else is to come in 2024?
Lean’s widgets offer the user a very flexible way of presenting data in an interactive graphical way. One application: I am very much hoping that this year will be the year that I will be able to start doing high school level geometry interactively in Lean; I give talks in schools about the Natural Number Game but I would like to write some new material about how to interact with statements such as “angle at centre equals twice angle at circumference” (proving it, using it) in Lean: there are some subtleties here which are not usually explained to schoolchildren (such as the difference between oriented and unoriented angles) and which would be exposed by a formal approach.
As far as mathematics goes, my team at Imperial are currently working on Tate modules, Selmer groups, the local and global Langlands program, commutative algebra, Lie algebras and more. When I start working full time on Fermat’s Last Theorem this will push the development of more of this kind of mathematics in Lean. There seems to be a coherent plan developing on the Lean Zulip for getting a basic theory of L-functions formalised (thanks to David Loeffler, Michael Stoll and others); one natural goal would be results like Cebotarev’s density theorem, used in Fermat. Heather Macbeth in 2023 formalised the definition of Riemannian manifolds; I feel like differential geometry is another area which now has huge potential for growth. The FRO have made it clear that they want to support this push for more mathematics in Lean; any mathematician interested in joining the community might want to start by working through the free online mathematics in Lean textbook.
For plans in computer science-related topics in 2024, I would invite you to consult the FRO roadmap . One thing I like about that page is the broad vision which the FRO has: one of the goals is “enhancing its interface and functionality to cater to a wide range of users, from mathematicians and software developers to verification engineers, AI researchers, and the academic community.”
As always, the Lean community web pages are another place where people can begin to learn about Lean (including installation instructions and so on); anyone who wants to try a fast interactive type-based programming language for their project, or who wants to formalise some mathematics, is welcome to jump in, and ask questions on the Zulip chat. Full names are preferred, and the two rules which have emerged in our community are: stay on topic, and be nice. Beginner questions are welcome in the #new-members stream.

 and
and  ,
,  is the smallest number of people at a party you need, to find
is the smallest number of people at a party you need, to find  , (implying that the diagonal Ramsey number
, (implying that the diagonal Ramsey number  can be upper-bounded by
can be upper-bounded by  ). The research community attempted improvements to the problem of decreasing their upper bound, and in 1988 the first polynomial improvement was found by
). The research community attempted improvements to the problem of decreasing their upper bound, and in 1988 the first polynomial improvement was found by  . Conlon’s paper, giving the first super-polynomial improvement to the Erdős-Szekeres bound, was especially noteworthy and appeared in the Annals of Mathematics. But despite all of these successes, the question of decreasing the base of the exponent in the bound was still open. Is there a constant
. Conlon’s paper, giving the first super-polynomial improvement to the Erdős-Szekeres bound, was especially noteworthy and appeared in the Annals of Mathematics. But despite all of these successes, the question of decreasing the base of the exponent in the bound was still open. Is there a constant  for which
for which  ?
?  using a probabilistic argument which was itself groundbreaking, and gave rise to the field of probabilistic combinatorics. While a lower order improvement has been made to this, the base
using a probabilistic argument which was itself groundbreaking, and gave rise to the field of probabilistic combinatorics. While a lower order improvement has been made to this, the base 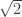 has not been improved, giving a wide gap between the lower and upper bounds of
has not been improved, giving a wide gap between the lower and upper bounds of  .
.  such that for all
such that for all  . This paper is in the publication process, and this is the result which I formalised.
. This paper is in the publication process, and this is the result which I formalised.  .
. and
and  , both of which are still unknown, and the main result of this post doesn’t get us any closer. Nonetheless, as part of this project, I formalised bounds on some of the known small values of Ramsey numbers, including
, both of which are still unknown, and the main result of this post doesn’t get us any closer. Nonetheless, as part of this project, I formalised bounds on some of the known small values of Ramsey numbers, including  .
. however, the proof can be recovered using that
however, the proof can be recovered using that  can be made large enough.
can be made large enough.  which I’d love to see formalised.
which I’d love to see formalised.  , together with the Galois action. An attack on local class field theory is now viable.
, together with the Galois action. An attack on local class field theory is now viable.![RHom_{\mathbb{Z}[T^{-1}]}(\overline{\mathcal{M}}_{r'}(S), \widehat{V})](https://s0.wp.com/latex.php?latex=RHom_%7B%5Cmathbb%7BZ%7D%5BT%5E%7B-1%7D%5D%7D%28%5Coverline%7B%5Cmathcal%7BM%7D%7D_%7Br%27%7D%28S%29%2C+%5Cwidehat%7BV%7D%29&bg=ffffff&fg=333333&s=0&c=20201002) as the derived inverse limit of
as the derived inverse limit of 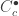 over all
over all 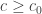 . Theorem 9.4 implies that
. Theorem 9.4 implies that the pro-system of cohomology groups
the pro-system of cohomology groups  is pro-zero (as
is pro-zero (as 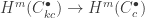 is zero). Thus, the derived inverse limit vanishes, as desired.”
is zero). Thus, the derived inverse limit vanishes, as desired.” , and the app will have a go at formalizing it. If the generated formal statement is correct, fantastic! You can copy and past the statement into your Lean source file. If it is incorrect, you can give the app feedback on what to fix in a natural, conversational way. Let’s see a few examples.
, and the app will have a go at formalizing it. If the generated formal statement is correct, fantastic! You can copy and past the statement into your Lean source file. If it is incorrect, you can give the app feedback on what to fix in a natural, conversational way. Let’s see a few examples.




 instead of my explicit instruction to use a field
instead of my explicit instruction to use a field 

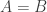 , and the argument is “That’s obvious — it’s true by definition of
, and the argument is “That’s obvious — it’s true by definition of  and
and  .” And then the computer works for quite some time until it confirms. I found that really surprising.
.” And then the computer works for quite some time until it confirms. I found that really surprising.
