
At university I was told about how to quotient by an equivalence relation. But I was not told the right things about it. This workshop is an attempt to put things right.
Models
Let me start by talking about things I learnt in my second and third year as an undergraduate. I went to a course called Further Topics in Algebra, lectured by Jim Roseblade, and in it I learnt how to take the tensor product 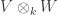

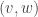
I came away with the impression that the key fact was the universal property, from which everything else could be proved, and that the model was basically irrelevant. To my surprise, I have learnt more recently that this is not exactly the whole truth. Here is an example, due to Patrick Massot. Let 

![R\to R[1/S]](https://s0.wp.com/latex.php?latex=R%5Cto+R%5B1%2FS%5D&bg=ffffff&fg=333333&s=0&c=20201002)
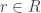
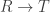


![R[1/S]](https://s0.wp.com/latex.php?latex=R%5B1%2FS%5D&bg=ffffff&fg=333333&s=0&c=20201002)

What is a quotient?
At university, in my first year, I was taught the following construction. If 



All the way through my undergraduate career, when taking quotients, I imagined that this was what was going on. For example when forming quotient groups, or quotient vector spaces, or later on in my life quotient rings and quotient modules, I imagined the elements of the quotient to be sets. I would occasionally look at elements of elements of a quotient set, something rarely done in other situations. I would define functions from a quotient set to somewhere else by choosing a random representative, saying where the representative went, and then proving that the construction was ultimately independent of the choice of representative and hence “well-defined”. This was always the point of view presented to me.
I have only relatively recently learnt that actually, this model of a quotient as a set of equivalence classes is nothing more than that — it’s just a model.
The universal property of quotients
Here’s the universal property. Say 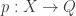

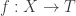

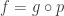
Example 1) Let 
Example 2) Let 
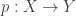


Example 2 shows that this construction of quotients using equivalence classes is nothing more than a model, and that there are plenty of other sets which show up naturally and which are not sets of equivalence classes but which are quotients anyway. The important point is the universal property. In contrast to localisation of rings, I know of no theorem about quotients for which the “equivalence class” model helps in the proof. The only purposes I can see for this “equivalence class” model now are (1) it supplies a proof that quotients do actually exist and (2) a psychological one, providing a “model” for the quotient.
I have had to teach quotients before, and students find them hard. I think they find them hard because some just basically find it hard to handle this whole “set whose elements are sets” thing. Hence even though the psychological reason was ultimately useful for me, and eventually I “got the hang of” quotients, I do wonder what we should be doing about the people who never master them. An alternative approach in our teaching is to push the universal property angle. I have never tried this. It might turn out even worse!
A worked example : maps from a quotient.
Here is the mantra which we hear as undergraduates and thus go on to feed our own undergraduates. The situation is this: we have some quotient object 

“Set of sets” variant:
The argument goes something like this:
“Recall that 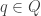



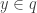

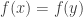
Is the student left wondering what the heck it means for a function to be “not well-defined”? How come nobody ever talks about any other kind of function before being “well-defined”? I thought the axiom of choice said that we can choose an element in each equivalence class all at the same time. How come we can’t just define 


Universal property variant:
The argument now looks like this.
“Recall that 

Is that the way to teach this stuff to undergraduates? Is it more confusing, less confusing, or maybe just differently confusing?
Today’s workshop
Lean has quotients of equivalence relations built in. This is not particularly necessary; it is an implementation decision which did not have to be done like this. One can certainly make quotients as types of equivalence classes (and indeed this has been done in mathlib, with the theory of partitions). However Lean also has an opaque quotient function, which creates another model of a quotient; we don’t know what the elements are, but we know the universal property and this is all we need.
Today we will learn about quotients by working through the explicit construction of the integers as the quotient of 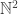
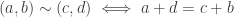

There is far far too much material to do in one 2-hour workshop, but I was on a roll. As ever, the material is here, in src/week_7.
Appendix: why not just use equivalence classes?
Mathematicians use quotients everywhere, so it’s kind of interesting that they have their own type, but why not just use the type of equivalence classes? Lean can make that type, and it’s possible to prove all the API for it — I’ve done it. So why explicitly extend Lean’s type theory to add a new quotient type? The answer seems to be this. The universal property for quotients is that if 
quotient.lift f h, which spits out g given f and a proof h that f is f = (quotient.lift f h) ∘ p, and the proof of this, remarkably, is rfl — it’s true by definition. This is what the baked-in quotient construction buys you. I used to think that this was really important (and indeed in the past I have claimed that this is a key advantage which Lean has over Coq). Now I am not so sure. It probably makes proofs a bit slicker occasionally — but nowadays I am less convinced by the idea of definitional equality in general — I’m happy to rewrite.

Something which is on my mind currently (for teaching reasons) is the following line of thought.
Suppose that we are told quotients exist in the world of Abelian groups and group homomorphisms, so that instead of ever mentioning philistine words like “coset” we say: given an Abelian group A and a (normal) subgroup N, there is an Abelian group A/N characterized by the universal property [BLAH].
Now suppose we are looking at rings. So I define the notion of an ideal, and then consider a ring R and an ideal J in it. I can certainly declare that there is some Abelian group R/J which is characterized by the universal property above. But how do I discuss the “quotient ring” structure that I now want to put on this Abelian group? It seems to me, although I may have overlooked/forgotten something, that one can only talk about R/J in terms of the maps out of it, so we need to factorize through $(R/J) \times (R/J)$, and now do I need to be currying? or discussing the monoidal structure in the category Ab?
through $(R/J) \times (R/J)$, and now do I need to be currying? or discussing the monoidal structure in the category Ab?
Or, speaking as an analyst, suppose I’m happy with quotients of vector spaces with respect to linear maps. Now let me go to the setting of Banach spaces, so I have equipped these vector spaces with some extra structure/gadgets that satisfy a bunch of conditions, and let me take a Banach space V with a closed subspace E. Then I know that up to isomorphism of vector spaces there is something called V/E. But how do I produce the quotient norm on V/E ? (Actually, in this case I guess really one introduces seminorms and then says that every seminorm that vanishes on E is dominated by (some multiple of) a particular one, but why does this extremal E-killing seminorm on V descend to a norm on V/E which after all was defined with reference to linear maps between vector spaces, and not sublinear ones?)
LikeLike
In Lean these problems are solved in the following way.
Say `X` is a type with an equivalence relation `r` (no groups or rings yet). I talked about `quotient.lift` which takes an `r`-equivariant map `X -> T` and produces a map `X/r -> T`. Now using the universal property one makes the following extremely convenient general definition (defined once and for all, shortly after the theory is set up). It’s a function `quotient.lift2` which given two types `X` and `Y` with equivalence relations `r` and `s`, and a map `f:X x Y -> T` which is constant on equivalence classes (i.e. x1 ~ x2 and y1 ~ y2 -> f(x1,y1)=f(x2,y2)), spits out a map `X/r x Y/s -> T`. This function is constructed via two calls to `quotient.lift` (and currying, as you say, which means interpreting f as an element of Hom(X,Hom(Y,T)), these just being maps of sets, or of course types in Lean’s case). In the ring case, one can now use this to descend (or “lift”, as Lean calls it 😦 ) multiplication to the quotient, using the equivalence relation defined by the ideal. In fact Lean also defines the variant `quotient.map2`, which given as input three sets X Y Z with equivalence relations r s t, and a function f:X x Y -> Z such that x1 ~ x2 and y1 ~ y2 -> f(x1,y1) ~ f(x2,y2), spits out a function X/r x Y/s -> Z/t (by composing with Z -> Z/t and then applying quotient.lift2).
The quotient norm on V/E is also defined via `quotient.lift`. One defines a map from V to the reals sending V to the inf of ||v+e|| as e ranges through E, checks easily that this map is constant on equivalence classes, and then applies quotient.lift to descend it to a map V/E -> reals.
I don’t know if this helps, but here are a bunch of links where all this is actually happening. You can search for any function at https://leanprover-community.github.io/mathlib_docs/ and see its documentation and also a link to the source code if you want to see its definition.
lift2: https://leanprover-community.github.io/mathlib_docs/init/data/quot.html#quotient.lift%E2%82%82 (you can see the type) with associated definition here https://github.com/leanprover-community/lean/blob/de35266fe59614a98ea8a3460a158583fde4fa0d/library/init/data/quot.lean#L153-L166 (which actually looks harder than I said! They seem to apply quotient.lift four times??).
map2: https://leanprover-community.github.io/mathlib_docs/data/quot.html#quotient.map%E2%82%82 (type and docstring) and if you click on “source” you can see it just uses `lift2`.
For quotient norms on vector spaces I think this is in mathlib somewhere, but in the Scholze project we needed the norm on the quotient of a normed abelian group by a
subgroup last week when we were doing all the normed group diagram chasing in chapter 9 of analytic.pdf (I note your earlier remark about normed diagram chases 😉 ) and I see that we didn’t even use the quotient.lift trick at all:
https://github.com/leanprover-community/lean-liquid/blob/a89aae6fbbf7c357756b04e893738dc782abb9a4/src/for_mathlib/normed_group_quotient.lean#L45-L47
We just used the mundane definition: we defined the norm of vbar in V/E to be the inf of the ||v|| for v in V lifting vbar. This stuff will shortly move into mathlib and then will replace any previous talks of norms on quotient vector spaces I guess, because it’s more general.
LikeLike
Lean has quotient by *arbitrary* relation built in, called `quot`; `quotient` is quotient by equivalence relation. `setoid.partition` depends on the built-in `quot` in the following way: functional extensionality is proved using `quot.sound`, and since sets are functions from a type to `Prop`, you need functional extensionality to prove the “Axiom of Extensionality” for sets, which e.g. is used to prove that the equivalence classes of related elements are the same.
LikeLike
All of this is true. The reason I didn’t say it is precisely because this is the sort of thing which is explained in Theorem Proving In Lean and to be honest I just found that, as a mathematician, all these details just confused me. It doesn’t matter *at all* to a working mathematician that `quotient.sound` is the axiom and that functional extensionality is involved. My presentation here is specifically written in a completely different way to TPIL, de-emphasizing the implementation issues and concentrating instead on how to make the standard constructions which a mathematician will need when making and proving things about some kind of quotient object.
LikeLiked by 1 person
Fair enough; I think my issue was mainly with the sentence “Lean also has an opaque quotient function”; there’re no nontransparency or hidden details going on, it’s just something that’s given as axiom. “Also” suggests that `quotient` is something parallel/alternative to the partition construction, but in fact it’s more fundamental in Lean. Together they made me think that the “opaque quotient function” is something different from the “built in” quotient at the beginning of the paragraph, which confused me, so I wrote the above comment to clarify it, but now I see you meant the same thing.
LikeLike
This is much more complicated than using the model for R[1/S], but it’s a sort of argument that does get used so I wonder if it can be “Lean”-ified:
Somehow the key thing is:
Lemma: if A_i is a filtered system of rings, then the kernel of the map from A_0 to A=\colim A_i is the union of the kernels.
You could prove this from some ‘construction’ of the filtered colimit, but if we’re building up everything “categorically” we should decide if that’s really where we want to resort to a construction. Maybe not yet: instead, observe that this is implied by the statement that pullbacks of sets preserve filtered colimits. Actually, pulling back along f: Y’–>Y preserves all colimits viewed as a functor f^*: Set_{/Y}–>Set_{/Y’}. That can be proved by an honest construction of the right adjoint, which seems somehow more fundamental: namely, given X’–>Y’ define X as the set {(y, g): g: f^{-1}(y)—>X’ is a section}. This construction gives the desired right adjoint to pulling back.
Again, that’s way too much nonsense, but it becomes better if you’re in some setting where an “explicit construction” is really annoying to build (like if you start putting \infty everywhere), and so you want to minimize how often you do it. In \infty-category land, we want to do a few basic, explicit constructions in the \infty-category of spaces which maybe depend on some model, and then never do explicit constructions again after that.
Anyway, let’s go back to rings. We have the map R—>R[1/S]. By nonsense, R[1/S] is the filtered colimit of the rings R[1/s] for s in S, so we are reduced to understanding the kernel of R–>R[1/s]. By nonsense again, R[1/s] is the colimit of multiplication by s on R, so the claim follows by the lemma again.
Who knows if this was helpful/useful/interesting/etc…
LikeLike
whoops- I made the usual mistake of confusing “base change preserves colimits” with commuting pullbacks with some colimit… so disregard the thing about “this is implied by the statement that pullbacks of sets preserve…” until the end of the paragraph. Nevertheless, the fact that filtered colimits of sets commute with finite limits seems somehow more fundamental than the explicit construction of R[1/S].
LikeLike